source distribution is broken
10 aug 2014


motivation
source and binary distribution in linux distributions is outdated and nobody is doing anything [tm].
problem
today i was packaging prosody [0] for nixos linux and wondered why
lua-socket 2.0.2 wasn’t working as expected. the solution was pretty
easy: it seems that 2.0.2 is just outdated and other distributions as
ubuntu [2] and fedora core [3] do use
[luasocket_3.0~rc1.orig.tar.gz] or
lua-socket-3.0-0.6rc1.fc21.x86_64.rpm respectively. also
both repos don’t state where they got the source code form which is not
only annoying but also dangerous since i now don’t know what
modifications either distribution included!
the issue: [1] does not have a 3.x release nor can i find the RCS used for development.
diego’s homepage [1] states:
Last modified by Diego Nehab on
Wed Oct 3 02:07:59 BRT 2007
now, what can we do?
seems like a abandoned project, as so often…
or a different example:
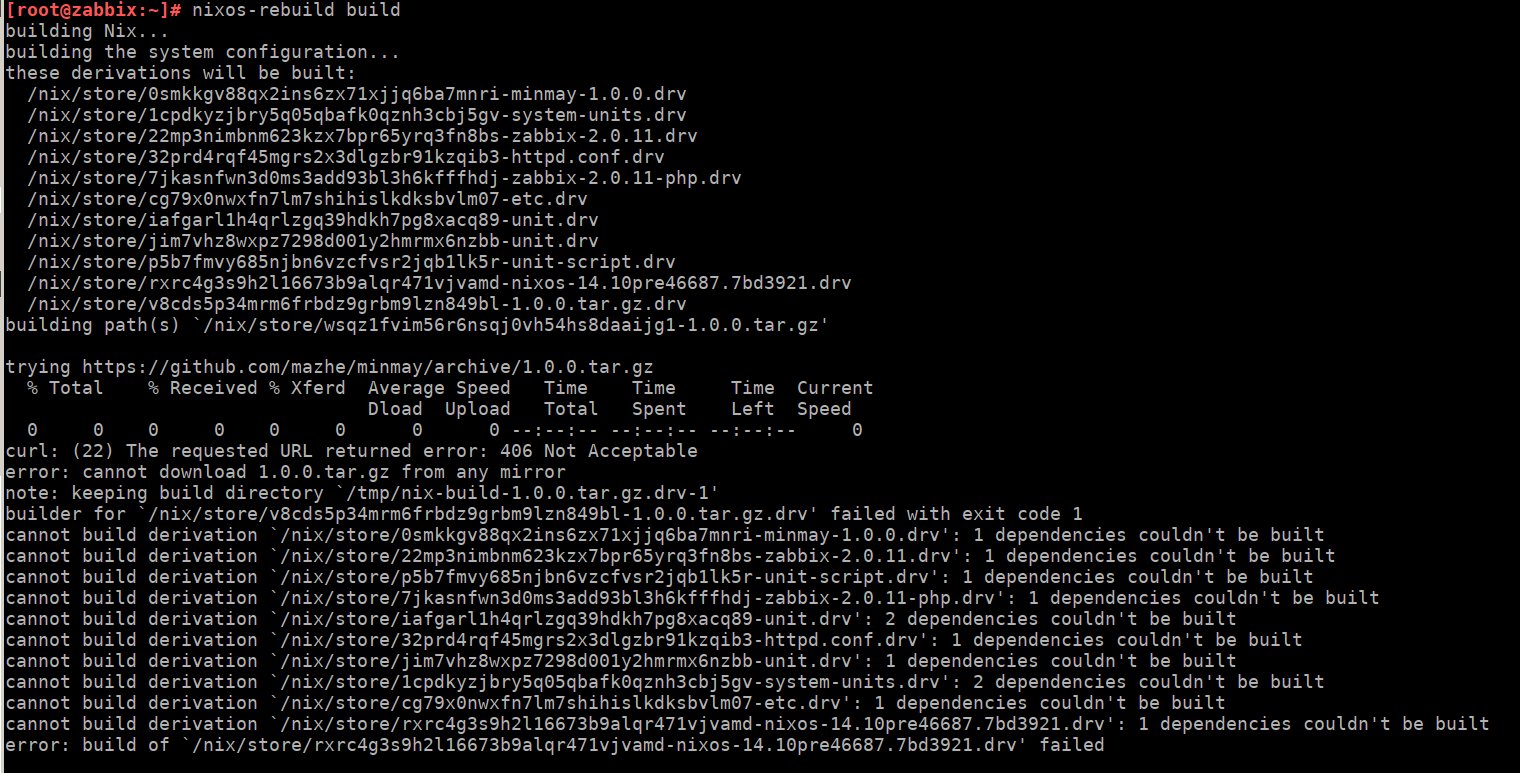
pkgs/development/libraries/minmay/default.nix states:
meta = {
homepage = "https://github.com/mazhe/minmay";
license = stdenv.lib.licenses.lgpl21Plus;
description = "An XMPP library (forked from the iksemel project)";
};mazhe removed minmay, probably unknowingly that the nixos distribution still was using this minmay 1.0.0 release from this repo, see https://github.com/mazhe/minmay/. or maybe mazhe didn’t find any other release of minmay, forked it on github.com and made a release himself.
in case [1] is abandoned it would be a good idea to:
- give lua-socket a new home - github.com would be a good idea IMHO
- create a ‘third party release’ on a neutral host like github.com [4], which does not depend on a distribution
in fact, we as a community don’t have any good reliable way to have access to virtually any project over a large period of time.
software distribution today
first, let’s have a look at how software distribution is done in different linux distributions:
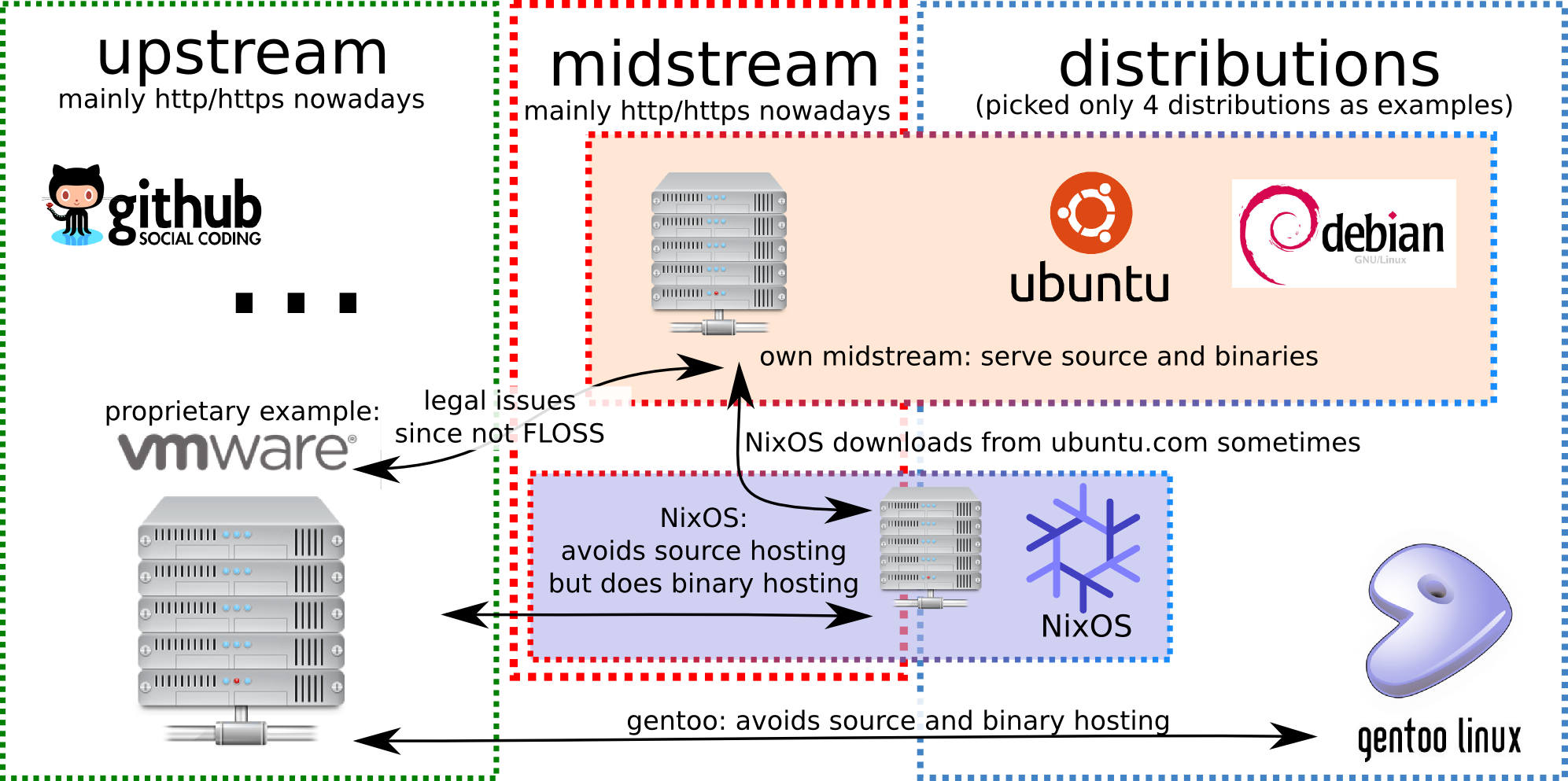
as shown in the picture above:
- terminology
- upstream (usually the developers)
- downstream (usually the distributions or users)
- midstream (a hypothetical platform between upstream and downstream)
- we do not have a common cache for source code
- we do not have a common cache for binaries (this would be more complicated, yet possible)
and most horrible yet:
- we still use http GET requests for downloads and not torrent-like technologies! most horrible on my android smartphone when i run out of space i can download new version of a program, then the installation fails as there is not enough space. next time it needs to redownload the same application again - WTF?!
proposal
shipping source/binary data must be redone.
shipping code/binaries
i thought about mixing GIT with the torrent technology, so that every time a new release happens, we just add it to a giant GIT database. i also propose that we need a meta layer between upstream (the developers) and downstream (the distributions or endusers). i’d like to call this midstream and ubuntu’s launchpad, github.com and similar platforms are pretty close to what midstream would do.
favoured technologies:
- GIT
- obnam [5] (interesting storage concept)
- p2p technology (torrent)
- GPG
wanted features:
free and open source (FLOSS)
we could standardize the deployment workflow this way
easy to scale
high reliability
signatures (like debian uses for their packages)
could be used for ‘binary distribution’ as well (my focus here is ‘source deployment’ though)
all linux distributions should download from there, instead directly from upstream. also, if a distribution downloads the code, it effectively (like in torrents) is now a new node also hosting the code for as long as users access the code
we could also host metadata and QA there, i thought about:
- programming style analysis
- code security analysis
- reverse lookups to point out in which distributions the code is used
- store compile logs, like: http://hydra.nixos.org/project/nixops
- using GIT directly with:
git clone --depth 1 --branch <branch> url; this avoids the usage of tar.gz|bz2|xv completely - project activity, age analysis of overall code
- even with a micro payment system or something like bug bounty
i want to outline that there is apt-p2p [6] already, which is AFAIK used for binary distribution of deb files and not used for source distribution. i could be wrong though.
hashing the downloads
when packaging software for nixos, we do ‘source deployment’ on the developers machine. when the nix-expression gets into nixpkgs, hydra will do ‘source deployment’ again. and in most cases hydra will produce a binary substitute (a NAR file) which is lika a DEB file on ubuntu.
how the hash is used
when doing ‘source deployment’, most often we would be using fetchurl, like below:
src = fetchurl {
url = "http://downloads.sourceforge.net/project/pdfgrep/${version}/${name}.tar.gz";
sha256 = "6e8bcaf8b219e1ad733c97257a97286a94124694958c27506b2ea7fc8e532437";
};the given sha256 checksum is given by the packager and
every time someone needs to do ‘source deployment’ again, this sha256sum
is used to verify the download given by the url. ebuilds
used by portage on gentoo also implement checksums of downloads this
way.
the problem
github.com, sourceforge.net and similar sites often create/recreate containers like .tar.gz or .zip on demand (cause unknown) and therefore the same container changes hashes over time, altough it still contains the same files. github.com features a new release system [4] which addresses this problem.
what we really need:
- a container agnostic hashing system
- independent of file order inside the container
- independent of compression mechanism
- the checksum mechanism often covers more than we need:
- on nixos we don’t need file attributes (like creation dates, owners, groups, permissions)
possible solution
since we have to checksum the input for sanity/reproducibility we
can’t just rely on a md5sum/sha256sum of the (compressed?) container.
maybe we could ‘deserialize’ the (compressed?) archives into /nix/store,
then build a NAR file of it and use the NAR’s hash to compare it to
sha256 (doing so would remove all superfluous attributes
like (timestamps, ownership, file order in the container, compression
artifacts, compression mechanism, container format issues).
advantage/disatvantage:
pro:
- we would cover all compression and container technologies this way
- this holds true for all kind of RCS checkouts as well
- it would ignore all attributes we are not interested in (see list above)
con:
- this would consume more I/O and CPU time: to compute the hash since it would require to re-serialize it again and compute the hash based on that
note: a different interesting approach would be to maintain a list of files per container with respective checksums per file. the overall checksum would be the sum of all the single checksums
summary
we do need distribution agnostic source code storage systems which scale well and have a high reliability. we also need to alter the way we build the checksums of source code containers.
update: (18.8.2014) i've been talking to aszlig and he mentiones that we have <tarballs.nixos.org> which i didn't know of so if hydra was able to build the nix expression it would cache the tarball there. but i still don't think that these tarballs can be accessed by a normal user doing source deployment on his development machine. so in case a tarball changes hashes again, we still have to alter the checksum in the nix expression.i would love to see more direct GIT usage in nixpkgs, since i think that doing explicit releases via containers is a waste of human time. this should be automated and containers releases should only be used to make source or binary deployment more efficient.
links
- [0] http://prosody.im/
- [1] http://w3.impa.br/~diego/software/luasocket/home.html
- [2] http://packages.ubuntu.com/trusty/lua-socket
- [3] http://rpm.pbone.net/index.php3/stat/3/srodzaj/1/search/lua-socket
- [4] https://github.com/blog/1547-release-your-software
- [5] http://obnam.org/
- [6] http://www.camrdale.org/apt-p2p/